Here are a few common misconceptions about SDN controller management and scalability.
#1: Either Proactive mode or Reactive mode
When an SDN controller wants to enforce a set of rules or a policy on a forwarding element, it uses the southbound API, OVSDB, OpFlex, OpenFlow or others. In OpenFlow this process is called flow installation and it can be done using different methods: proactive, reactive or mixed (aka hybrid approach).

Proactive
During bootstrap, the controller installs all flows and pipelines (multi-table entries) into all the forwarding elements. The flows must cover all possible scenarios.
Whenever there is a change in the network, the controller removes or installs flows where necessary.
Reactive
When a packet arrives in a switch, a look-up is performed on the flow tables.
If there is no match and the switch is connected to a controller, it will forward the packet (either with or without its payload) to the controller.
In OpenFlow, this is called a PACKET_IN message.
It is also possible to create rules that forward the packet to the controller when matched and we call that...
If there is no match and the switch is connected to a controller, it will forward the packet (either with or without its payload) to the controller.
In OpenFlow, this is called a PACKET_IN message.
It is also possible to create rules that forward the packet to the controller when matched and we call that...
Mixed Proactive / Reactive
With the mixed approach, you can benefit from the best of both worlds, achieving a balance between dynamic management and performance.
For frequently-used and rarely-modified flows, you install a pipeline and flows proactively.
For unmatched flows, or for flows that you want to handle in-line in your SDN application, you install a flow to forward the packet to the controller.
This mixed approach allows the controller to focus on making real-time dynamic decisions only on the traffic that requires it (reactive), while leaving the heavy-lifting of the majority of the traffic to the real-time forwarding element (proactive).
In addition, with this approach you can avoid over-provisioning the forwarding element with flows that are rare, thus dramatically reducing the number of entries in the flow tables.
#2: Lack of Scalability and High Availability
In SDN, the control plane (i.e. the SDN Controller) is separated from the data plane (i.e. the Forwarding Elements).
Due to the centralized nature of control in SDN, we now need to support high availability and redundancy of the Control Plane.
In OpenFlow, the Forwarding Element (the Switch) connects to the controller via TCP or via TLS for secure channels.
Up until OpenFlow v1.2, whenever the connection to the controller was lost, the switch would lose the ability to forward PACKET_IN messages to the controller, thus having to drop all unmatched traffic or handle it in the NORMAL switch (only in switches that implemented the dual nature).
This non-deterministic approach would yield unpredictable network behavior
while the controller was unavailable.
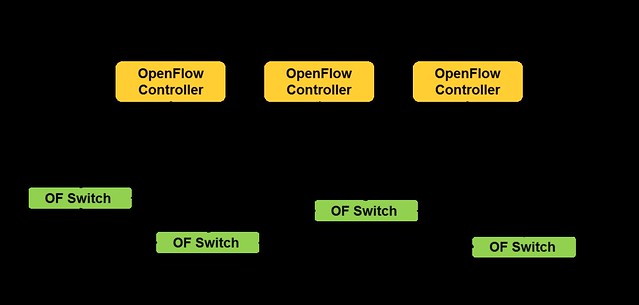
OpenFlow v1.2 introduced the capability of working with multiple controllers.
The Master and Slave modes provide a mechanism for Active-Passive high availability, whereas the Equal mode provides an Active-Active model.
With the multi-controller capability, we gained the control plane high availability we needed, improved reliability, fast recovery from failure and controller load balancing.
Utilizing the two mechanisms I covered - Mixed-Mode and Multi-Controller - is the key to designing really big scale SDN applications.
If you take care to design your application to be stateless (whenever possible) and share nothing (or little) with other controller instances you can benefit from the Reactive mode where any instance can handle any flow.
The Master and Slave modes provide a mechanism for Active-Passive high availability, whereas the Equal mode provides an Active-Active model.
 |
| OpenFlow multiple controllers |
#3: You cannot design SDN Applications for Really Big Scale
Utilizing the two mechanisms I covered - Mixed-Mode and Multi-Controller - is the key to designing really big scale SDN applications.
If you take care to design your application to be stateless (whenever possible) and share nothing (or little) with other controller instances you can benefit from the Reactive mode where any instance can handle any flow.
In my opinion, the best approach for achieving minimal controller response latency and maximal bandwidth while keeping the dynamic allocation of flows, is by using all of these mechanisms together.
When you add to that the OVS OpenFlow extensions and the dual-nature Hybrid OpenFlow capability (which I covered in my previous post), you can really gain a dramatic performance and management boost.
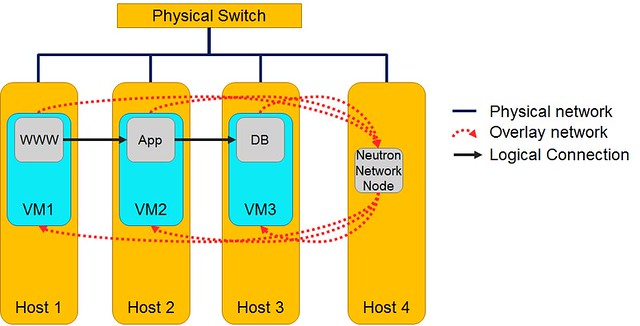
In my next post I will demonstrate how we utilized these design guidelines and capabilities in a prototype for an alternative to Neutron's L3 Distributed Virtual Router.
When you add to that the OVS OpenFlow extensions and the dual-nature Hybrid OpenFlow capability (which I covered in my previous post), you can really gain a dramatic performance and management boost.
In my next post I will demonstrate how we utilized these design guidelines and capabilities in a prototype for an alternative to Neutron's L3 Distributed Virtual Router.










{kind=link}