In the previous post we explained why we chose the distributed control path approach (local controller) for Dragonflow.
Lately, we have been getting a lot of questions about DHCP service, and how it could be made simpler with an SDN architecture.
This post will therefore focus on the Dragonflow DHCP application (recently released). Lately, we have been getting a lot of questions about DHCP service, and how it could be made simpler with an SDN architecture.
We believe it is a good example for Distributed SDN architecture, and to how policy management and new advanced network services that run directly at the Compute Node simplify and improve the OpenStack cloud stability and manageability.
Just as a quick overview, the current reference implementation for DHCP in OpenStack Neutron is a centralized agents that manages multiple instances of the DNSMASQ Linux application, at least one per subnet configured with DHCP.
Each DNSMASQ instance runs in a dedicated Linux namespace, and you have one per a tenant's subnet (e.g. 5 tenants, each with 3 subnets = 15 DNSMASQ instances running in 15 different namespaces on the Network Node).
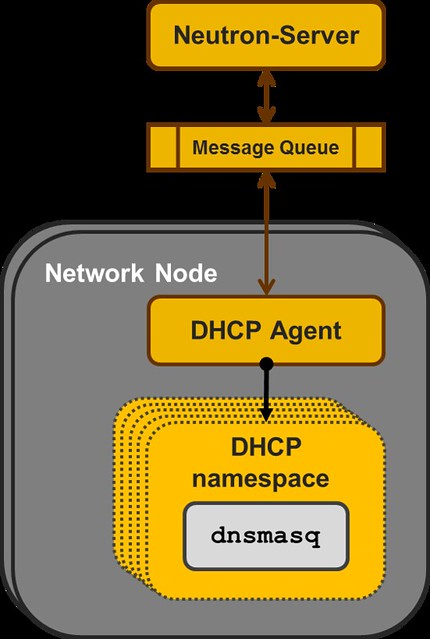 |
| Neutron DHCP Agent |
The concept here is to use "black boxes" that each implement some specialized functionality as the the backbone of the IaaS.
And in this manner, the DHCP implementation is similar to how Neutron L3 Agent and the Virtual Router namespaces are implemented.
However, for the bigger scale deployments there are some issues here:
Management - You need to configure, manage and maintain multiple instances of DNSMASQ. HA is achieved by running an additional DNSMASQ instance per subnet on a different Node which adds another layer of complexity.
Scalability - As a centralized solution that depends on the Nodes that run the DHCP Agents (aka Network Node), it has serious limitations in scale. As the number of tenants/subnets grow, you add more and more running instances of DNSMASQ, all on the same Nodes. If you want to split the DNSMASQs to more Nodes, you end-up with significantly worse management complexity.
Performance - Using both a dedicated Namespace and a dedicated DNSMASQ process instance per subnet is relatively resource heavy. The resource overheads for each tenant subnet in the system should be much smaller. Extra network traffic, The DHCP broadcast messages are sent to all the Nodes hosting VMs on that Virtual L2 domain.
Having said that, the reference implementation DHCP Agent is stable mature and used in production while the concept we discuss in the next paragraph is in a very early stage in the development cycle.
Dragonflow Distributed DHCP
When we set up to develop the DHCP application for the Dragonflow Local Controller, we realized we had to first populate all the DHCP control data to all the relevant local controllers.
In order to do that, we added the DHCP control data to our distributed database.
More information about our database can be found in Gal Sagie's post:
Dragonflow Pluggable Distributed DB.
In order to do that, we added the DHCP control data to our distributed database.
More information about our database can be found in Gal Sagie's post:
Dragonflow Pluggable Distributed DB.
Next, we added a specialized DHCP service pipeline to Dragonflow's OpenFlow pipeline.

- A classification flow to match DHCP traffic and forward it to the DHCP Table was added to the Service Table
- In the DHCP Table we match by the in_port of each VM that is connected to a subnet with a DHCP Server enabled
- Traffic from VMs on subnets that don't have a DHCP Server enabled are resubmitted to the L2 Lookup Table, so that custom tenant DHCP Servers can still be used
- For packets that were successfully matched in the DHCP Table we add the port_id to the metadata, so that we can do a fast lookup in the Controller database, and then we forward the packet to the Controller
- In the Controller, we forward the PACKET_IN with the DHCP message to the DHCP SDN Application.
- In the DHCP Application, we handle DHCP_DISCOVER requests and generate a response with all the DHCP_OPTIONS that we send directly to the source port.
The diagram below illustrate the DHCP message flow from the VM to the local controller.
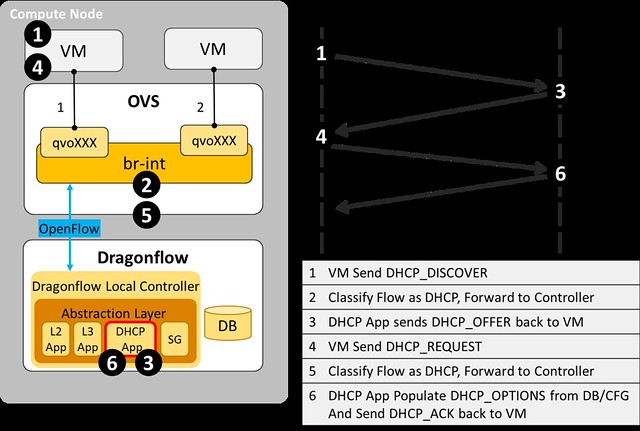 |
| DHCP message flow |
Benefits of Dragonflow Distributed DHCP
Simplicity - There is no additional running process(es). The one local controller on each compute node does it all, for all subnets and all tenants
Scalability - Each local controller deals only with the local VMs
Stability - One process per compute node is easy to make sure is running at all times
Performance - DHCP traffic is handled directly at the compute node and never goes on the network
And there are surely many more benefits to this approach, feel free to post them as comments.
I want it! How do I get it?
The source code of this newly developed service in available here, and you could try it today (just follow the Dragonflow installation guide).
We are currently working on improving the stability of the L2, L3 and DHCP services of the Dragonflow local controller for OpenStack Liberty release.
The Dragonflow Community is growing and we would love to have more people joining to contribute to its success.
For any questions, feel free to contact us on IRC #openstack-dragonflow