In a previous post I covered some misconceptions about SDN management and my view of the importance of the hybrid(proactive/reactive) model for scalability, and how we used this approach in the design of Dragonflow.
Today, i will discuss the two existing paradigms to SDN control path, and how it affects our road map in the Dragonflow project.
The first approach is the Centralized Controller. Here, a controller (or a cluster of them) manages all the forwarding elements in the system, and retains a global view of the entire network. Most SDN controllers today run this way (ODL, ONOS, as well as Kilo version of Dragonflow).
The second approach is the Distributed Control Path. Here, a local controller runs on each compute node and manages the forwarding element directly (and locally). Thus, the control plane becomes distributed across the network.

However, the virtual network topology needs to be synchronized across all the local controllers, and this is accomplished by using a distributed database.
Like everything else in life, there are advantages and disadvantages to each approach. So, let's compare:
Centralized Control Path
Pros
- The controller has a global view of the network, and it can easily ensure that the network is in a consistent, optimal configuration
- Simpler, agentless solution - Nothing needs to be installed on the compute nodes
- Any and all southbound APIs can be supported directly from the centralized controller (easier to integrate with legacy equipment)
Cons
- Added latency in newly established flows, becomes a bottleneck in large scale deployments
- Dependency on the controller cluster availability and scale
- All advanced services are handled centrally, instead of locally, perpetuating a bottleneck as the scale grows
- Large scale is usually controlled via BGP-based Confederations and multiple SDNC clusters which add more latency and complexity
Distributed Control Path
Pros
- You can manage policies and introduce advanced services locally on each compute node, since you already have a local footprint
- Significantly better scalability, now that you have the control plane completely distributed
- Significantly better latency during reactive handling of PACKET_IN
- Highly-available by design and no single-point-of-failure
- Easier to integrate Smart NIC capabilities on local host level
Cons
- Synchronization of the virtual network topology can be a challenge, as the amount of compute nodes increases
- No global view
- Extra compute is done on the local host
- If you have heterogeneous forwarding elements (e.g. legacy switches), you need to have a centralized controller that connects them to the distributed control plane (which can complicate the management)
What we chose and why
We decided earlier-on to go with a hybrid reactive/proactive model (against the widely-accepted proactive-only approach), as we saw that its advantages were overwhelming.
The winning point of the reactive mode, as we see it, is that it improves the performance of the datapath, taking the performance toll instead on the control path of newly-established flows. The main reason for that being a dramatic reduction of the number of flows that are installed into the forwarding element.
When combined with a pipeline that is deployed proactively, we could maximize the benefits of the reactive approach, while minimizing its cost.
However, like all solutions, at a certain scale it will break.

In very large deployments (e.g. a full datacenter), a central controller cluster becomes overwhelmed with the increase in volume of new connections.
A centralized controller made sense, while we were only handling new L3 connection path establishment (Dragonflow in Kilo).
However, when we came to add reactive L2 and other advanced services (like DHCP, LB, etc.), we realized that scaling the centralized controller cluster was becoming a huge challenge.
A centralized controller made sense, while we were only handling new L3 connection path establishment (Dragonflow in Kilo).
However, when we came to add reactive L2 and other advanced services (like DHCP, LB, etc.), we realized that scaling the centralized controller cluster was becoming a huge challenge.
A different approach must now be taken, and we believe this approach is to place a local controller on each compute node.
Now that the control path bottleneck was mitigated, the problem moves to the logical data distribution between all the local controllers.
To mitigate that, we believe we can reuse the reactive approach, by letting the local controllers synchronize only the data they actually need (in lazy mode) use key/value distributed db engines that provide low latency.
Sure, this will probably take some performance toll on the establishment of new flows, but we believe it will dramatically reduce the amount of data synchronization required, and therefore will take us to the next scalability level.
Sure, this will probably take some performance toll on the establishment of new flows, but we believe it will dramatically reduce the amount of data synchronization required, and therefore will take us to the next scalability level.
What we are doing in Dragonflow
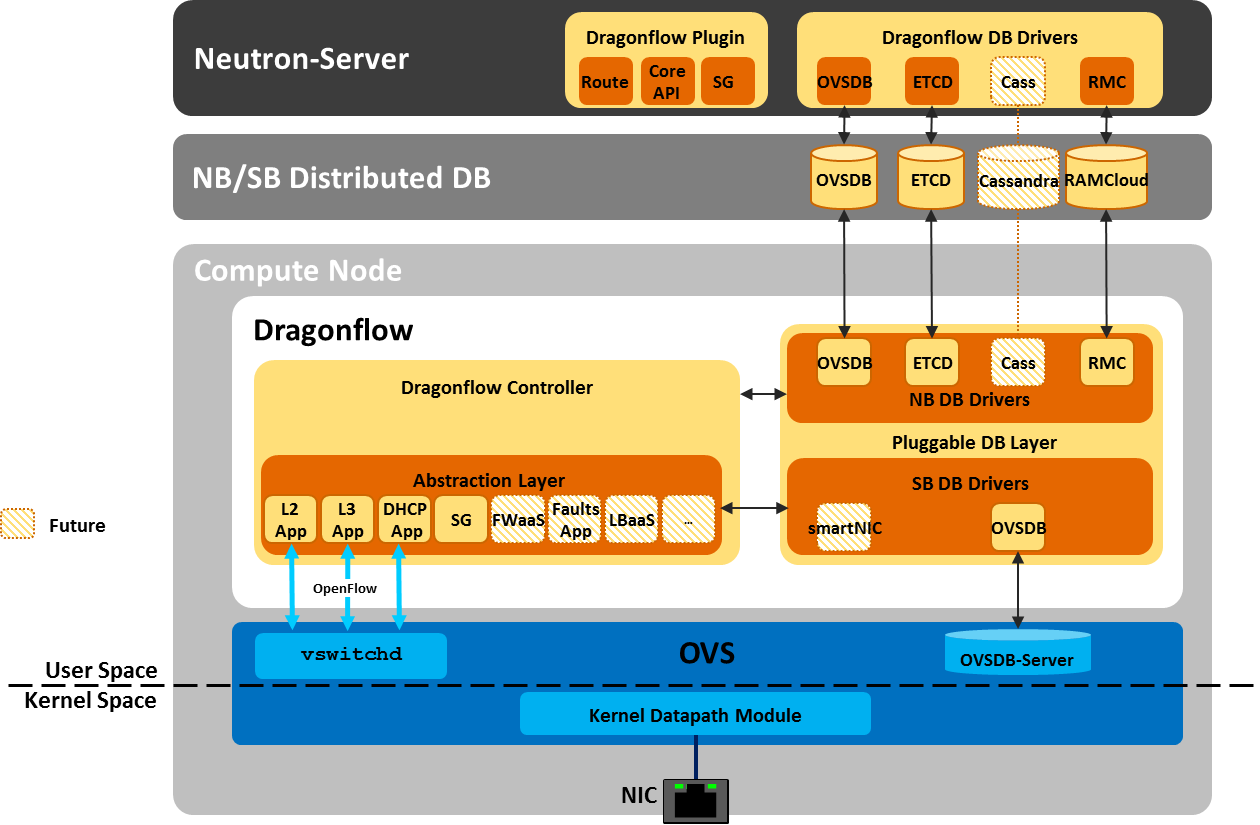
We are currently working on introducing reactive L2 and L3 model into the local Draongflow controller.
We are creating a pluggable distributed database mechanism to serve the logical data across the datacenter, which will enable the user to chose the best database to meet their specific needs and scale.
As always, we would love to have more people join the Dragonflow community and contribute to its success.
For additional information about the pluggable database layer, you can check out Gal Sagie's new blog post.
We are creating a pluggable distributed database mechanism to serve the logical data across the datacenter, which will enable the user to chose the best database to meet their specific needs and scale.
As always, we would love to have more people join the Dragonflow community and contribute to its success.
For additional information about the pluggable database layer, you can check out Gal Sagie's new blog post.
No comments:
Post a Comment