In the previous post we explained why we chose the distributed control path approach (local controller) for Dragonflow.
Lately, we have been getting a lot of questions about DHCP service, and how it could be made simpler with an SDN architecture.
This post will therefore focus on the Dragonflow DHCP application (recently released). Lately, we have been getting a lot of questions about DHCP service, and how it could be made simpler with an SDN architecture.
We believe it is a good example for Distributed SDN architecture, and to how policy management and new advanced network services that run directly at the Compute Node simplify and improve the OpenStack cloud stability and manageability.
Just as a quick overview, the current reference implementation for DHCP in OpenStack Neutron is a centralized agents that manages multiple instances of the DNSMASQ Linux application, at least one per subnet configured with DHCP.
Each DNSMASQ instance runs in a dedicated Linux namespace, and you have one per a tenant's subnet (e.g. 5 tenants, each with 3 subnets = 15 DNSMASQ instances running in 15 different namespaces on the Network Node).
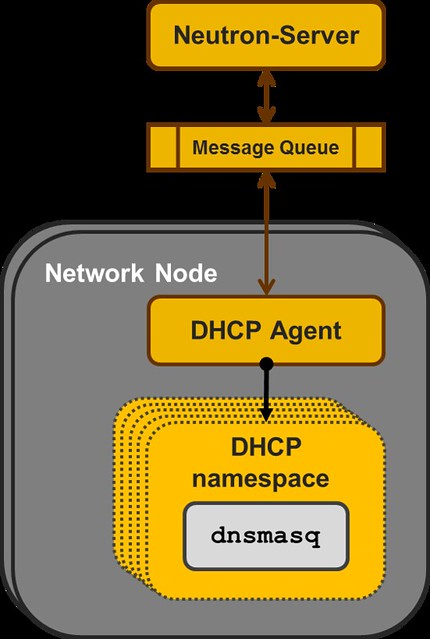 |
| Neutron DHCP Agent |
The concept here is to use "black boxes" that each implement some specialized functionality as the the backbone of the IaaS.
And in this manner, the DHCP implementation is similar to how Neutron L3 Agent and the Virtual Router namespaces are implemented.
However, for the bigger scale deployments there are some issues here:
Management - You need to configure, manage and maintain multiple instances of DNSMASQ. HA is achieved by running an additional DNSMASQ instance per subnet on a different Node which adds another layer of complexity.
Scalability - As a centralized solution that depends on the Nodes that run the DHCP Agents (aka Network Node), it has serious limitations in scale. As the number of tenants/subnets grow, you add more and more running instances of DNSMASQ, all on the same Nodes. If you want to split the DNSMASQs to more Nodes, you end-up with significantly worse management complexity.
Performance - Using both a dedicated Namespace and a dedicated DNSMASQ process instance per subnet is relatively resource heavy. The resource overheads for each tenant subnet in the system should be much smaller. Extra network traffic, The DHCP broadcast messages are sent to all the Nodes hosting VMs on that Virtual L2 domain.
Having said that, the reference implementation DHCP Agent is stable mature and used in production while the concept we discuss in the next paragraph is in a very early stage in the development cycle.
Dragonflow Distributed DHCP
When we set up to develop the DHCP application for the Dragonflow Local Controller, we realized we had to first populate all the DHCP control data to all the relevant local controllers.
In order to do that, we added the DHCP control data to our distributed database.
More information about our database can be found in Gal Sagie's post:
Dragonflow Pluggable Distributed DB.
In order to do that, we added the DHCP control data to our distributed database.
More information about our database can be found in Gal Sagie's post:
Dragonflow Pluggable Distributed DB.
Next, we added a specialized DHCP service pipeline to Dragonflow's OpenFlow pipeline.

- A classification flow to match DHCP traffic and forward it to the DHCP Table was added to the Service Table
- In the DHCP Table we match by the in_port of each VM that is connected to a subnet with a DHCP Server enabled
- Traffic from VMs on subnets that don't have a DHCP Server enabled are resubmitted to the L2 Lookup Table, so that custom tenant DHCP Servers can still be used
- For packets that were successfully matched in the DHCP Table we add the port_id to the metadata, so that we can do a fast lookup in the Controller database, and then we forward the packet to the Controller
- In the Controller, we forward the PACKET_IN with the DHCP message to the DHCP SDN Application.
- In the DHCP Application, we handle DHCP_DISCOVER requests and generate a response with all the DHCP_OPTIONS that we send directly to the source port.
The diagram below illustrate the DHCP message flow from the VM to the local controller.
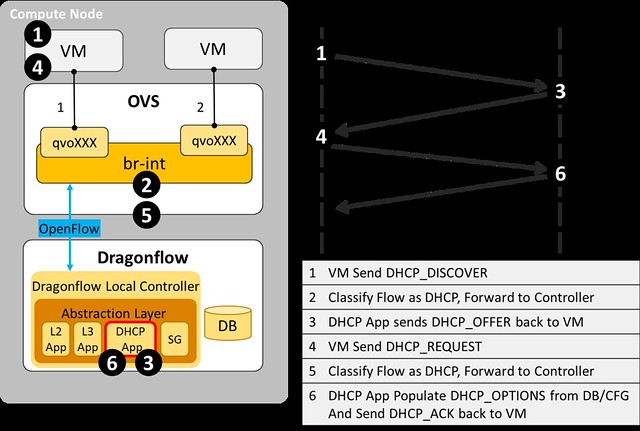 |
| DHCP message flow |
Benefits of Dragonflow Distributed DHCP
Simplicity - There is no additional running process(es). The one local controller on each compute node does it all, for all subnets and all tenants
Scalability - Each local controller deals only with the local VMs
Stability - One process per compute node is easy to make sure is running at all times
Performance - DHCP traffic is handled directly at the compute node and never goes on the network
And there are surely many more benefits to this approach, feel free to post them as comments.
I want it! How do I get it?
The source code of this newly developed service in available here, and you could try it today (just follow the Dragonflow installation guide).
We are currently working on improving the stability of the L2, L3 and DHCP services of the Dragonflow local controller for OpenStack Liberty release.
The Dragonflow Community is growing and we would love to have more people joining to contribute to its success.
For any questions, feel free to contact us on IRC #openstack-dragonflow
Neutron's DHCP implementation is far from being perfect, but there are a number of inaccuracies with issues as stated above, and you are depicting a picture far worse than it actually is.
ReplyDeletea) Management - You need to configure and manage multiple instances of DNSMASQ. One of the known stability issues in Neutron is related to these processes sometime silently & inexplicably dying.
Nothing dies inexplicably nor silently, and you should know that Neutron has built-in process monitors that revive processes should they die.
b) HA is achieved by running an additional DHCP server instance per subnet on a different Network Node which adds another layer of complexity.
HA is achieved by running multiple dhcp servers per network; yes you may need more than one network node, but you can distribute the dhcp function across compute nodes too. This is a deployment option you have.
c) Scalability - As a centralized solution that depends on the Network Node, it has serious limitations in scale. As the number of tenants/subnets grow, you add more and more running instances of DNSMASQ, all on the same Network Node. If you want to split the DNSMASQs to different Network Nodes, you end-up with significantly worse management complexity.
The reference architecture based on network nodes is 'one' deployment architecture; it is not the only one. As I mentioned above you can hit the sweet spot for your environment if you know what you are doing.
Having said that, Neutron community developers have also worked in pushing the architecture boundaries with:
https://blueprints.launchpad.net/neutron/+spec/distributed-dhcp
d) Performance - Using both a dedicated Namespace and a dedicated DNSMASQ instance per subnet is very resource heavy.
Without actual numbers and what you mean by heavy, this is a very shallow statement: I could search and replace Namespace and DNSMASQ with Dragonflow and I might get away with it just as well. But I typically refrain from making such claims. Namespaces are very lightweight and process isolation is very lean: you can run thousands of networks on a single nodes before it goes belly up, but then again that depends from a multitude of variables.
Do not get me wrong: I think that controller-based approach like Dragonflow are great and I very much welcome these types of initiatives within the OpenStack ecosystem. Choice is great and I wish we had more of these SDN-based options going around as we see today when Neutron had started.
You don't have to label a choice as 'bad' to promote another, they are all choices after all and if you are impartial you'll have better chances to be heard.
Armando Migliaccio - aka armax
Neutron Project Team Lead
Thanks for the comment, Armando.
DeleteThe stock DHCP is not a bad solution, it works and it's probably good enough for many users.
But As you said, it is all about choices, and in this post we highlighted why we chose a different path from the stock DHCP implementation, we wanted to show the problems in that implementation that lead us and others to seek distributed DHCP solution.
I think that comparison is inevitable when you have multi choice and alternative implementations, but by no means I indented to say that one implementation is “bad”.
In the end I agree it is all about the numbers what is the scale that you seek, I will try to get the numbers that lead my companies public cloud solution to look for a distributed DHCP solution and not use the DHCP agent and if possible publish them.
I think a Namespace + (vNIC) + dnsmasq process at the least per subnet, extra network broadcast traffic for the DHCP messages , maintenance of the DHCP agents are significant resource overhead, when compared to a local controller handling it without any overhead outside the local VM compute node.
Armando,
DeleteI agree with you that some parts could have been rephrased better, but i wanted to add my point of view on this.
Management / HA / Scalability
The root problem here, in my eyes, is the big amount of entities that are used to implement
a specific feature.
(In our case all these namespaces with dnsmasq)
This brings many problems in terms of deployment and configuration.
It makes debugging/management hard for the operators and users, there are many possible spots
of failures and when management/monitoring software for OpenStack mature it will be hard for them to keep track.
Yes, as you mentioned there are solutions (for example the process monitor) and you can deploy things at various different points in your setup but this again makes the code more complex and harder to maintain, it introduce much more possible failure scenarios.
It makes it harder for the deployers to find this "sweet spot" as you call it.
For the HA, i think that a problematic behaviour in the reference implementation is that HA design is being looked in as a per feature/area basis instead of in a global implementation look.
Up until now, these solutions involve duplicating the entities involved (the dnsmasq namespaces in this case and the virtual router namespaces in the L3 case).
This again introduce all the above problems (management complexity/ code complexity) in addition to now added synchronisation issues and all the various different implementations and dependencies used to solve the redundancy for each individual feature.
Performance wise, i agree with you that posting declarations without actual experiments doesnt make much sense, but after spending a lot of time in performance improvement area i can honestly say that even with tests its hard to get a clear picture because there are so many different cases and environments possibilities that its hard to get a conclusive statement.
Thats why i think its important to understand the alternative and the various solutions.
I think the solution described by Eran solves many of the problems mentioned above and also decrease broadcast/unicast DHCP traffic and the resource consumptions (which when you look at the overall deployment, adds up even if it doesnt look like it when you just consider DHCP).
For the distribution of dnsmasq namespaces to the compute nodes, this solves the traffic problem but makes all the other problems much worse and also introduce so many other possible abnormal scenarios when we start synching everything using RPC. (not to mention HA/code complexity)
Yes, there are also advantages to the current solution. mainly the fact that its well tested and already deployed.
I think however that we all strive to make Neutron implementation better in an open way, and the approach proposed here in addition to other projects which goes with the same path all try to do so in an open source way (At least thats my own intention and goal)
I agree with you that we must strive to be very accurate in terms of our descriptions because
its hard for the users which don't have enough time to invest in investigating each different implementation (maybe we should make something formal in this area)
I am personally very happy to see all the possible alternatives implementations for Neutron and try to get familiar with as many as my bandwidth allow me and also participate as an active contributor, i think we should continue to be judgemental to the various designs, each has its pros and cons but we should also strive to solve things in a simple way which is easy to manage/maintain by our users.
Just my take on the things :)